library(tidyverse)
library(readxl)
library(janitor)Data format conversions
3.1 Long to wide format
There are two main ways how the data can be organised across rows and columns. Wide or long format. We will show you an example of spruce forest data, where we recorded plant species in several sites and at each site we also estimated their abundance, here approximated as percentage cover (higher value means that the species covered larger area of the surveyed vegetation plot, but we do not give the area itself, just value relatively to the total area, i.e. percentage of total area). The covers of species might overlap, as they grow in different heights.

Wide format is more conservative and used in many older packages for ecological data analysis. In our example we list all species and the colums are used to indicate their abundance at each site. This is the way you need to prepare your species matrix for ordinations in vegan. However, wide format has also many cons.
One of them is the size of the file. In the example above, there are abundance of given plants in each of the site. When the species is present in just one site, here Trientalis europaea, it is still keeping space across the whole table, where there can be hundreds or thousands of sites. The table code is then of course memory demanding. Another disadvantage is that you cannot add easily new information to the listed species. If you for example want to separate species that are in a tree vegetation layer (recognised in vegetation ecology as 1), herb layer (6) and moss layer (9), you would have to add this information to the name of the species e.g. Picea_abies_1.
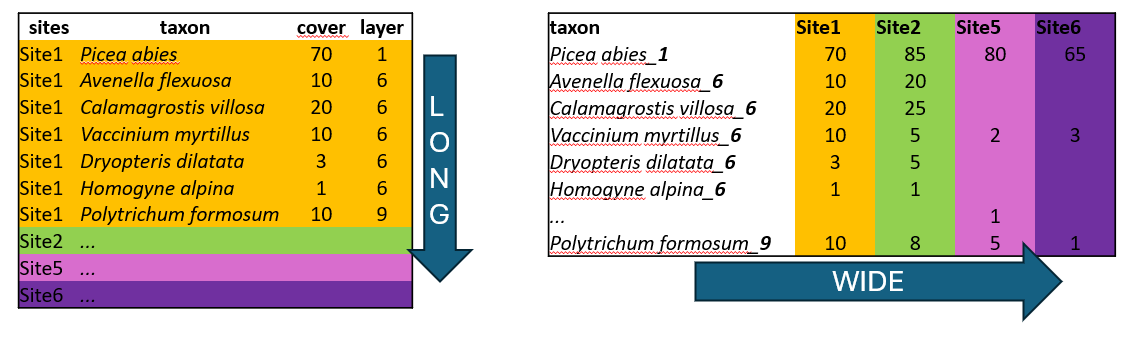
Long format in contrast, is great for handling large datasets. We can also add any information, describing the data, such as vegetation layers, growth forms, native/alien status etc. After that we can very simply filter, summarise and calculate further statistics.
We will upload the species data saved in a long format and transform it into a matrix =wide format, so that it can be used in specific ecological analyses e.g. in vegan. (For wide to long see study materials)
spe <- read_csv("data/spe_merged_covers.csv") Rows: 2277 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): species
dbl (3): releve_nr, layer, cover_perc
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.tibble(spe)# A tibble: 2,277 × 4
releve_nr species layer cover_perc
<dbl> <chr> <dbl> <dbl>
1 1 Acer campestre 1 20
2 1 Acer campestre 7 0.5
3 1 Acer platanoides 7 0.1
4 1 Anemone 6 0.5
5 1 Bromus ramosus agg. 6 0.1
6 1 Carex digitata 6 3
7 1 Carex michelii 6 0.1
8 1 Carex montana 6 0.5
9 1 Carpinus betulus 7 0.5
10 1 Cephalanthera damasonium 6 0.1
# ℹ 2,267 more rowsWe can see that there are plant species names sorted by releve_nr, where each number indicates a vegetation record from one specific site (can be also called vegetation plot or sample). We may need to change the species names to be in the compact format, without any spaces, just underscores. For this we will use mutate function with str_replace (for string specification) indicating that each space should be changed to underscore and we will directly apply it to the original column.
spe %>%
mutate(species = str_replace_all(species, " ", "_"))# A tibble: 2,277 × 4
releve_nr species layer cover_perc
<dbl> <chr> <dbl> <dbl>
1 1 Acer_campestre 1 20
2 1 Acer_campestre 7 0.5
3 1 Acer_platanoides 7 0.1
4 1 Anemone 6 0.5
5 1 Bromus_ramosus_agg. 6 0.1
6 1 Carex_digitata 6 3
7 1 Carex_michelii 6 0.1
8 1 Carex_montana 6 0.5
9 1 Carpinus_betulus 7 0.5
10 1 Cephalanthera_damasonium 6 0.1
# ℹ 2,267 more rowsWe have the condensed name with underscores, but there are still more variables in the table. We can either remove them or merge them to be included in the final wide format. Here we will go a bit against tidy rules and add the information about the vegetation layer directly to the variable Species using unite function from the package tidyr which merges strings from two or more columns into a new one: A+B =A_B. Default separator is again underscore, unless you specify it differently by sep=XX argument.
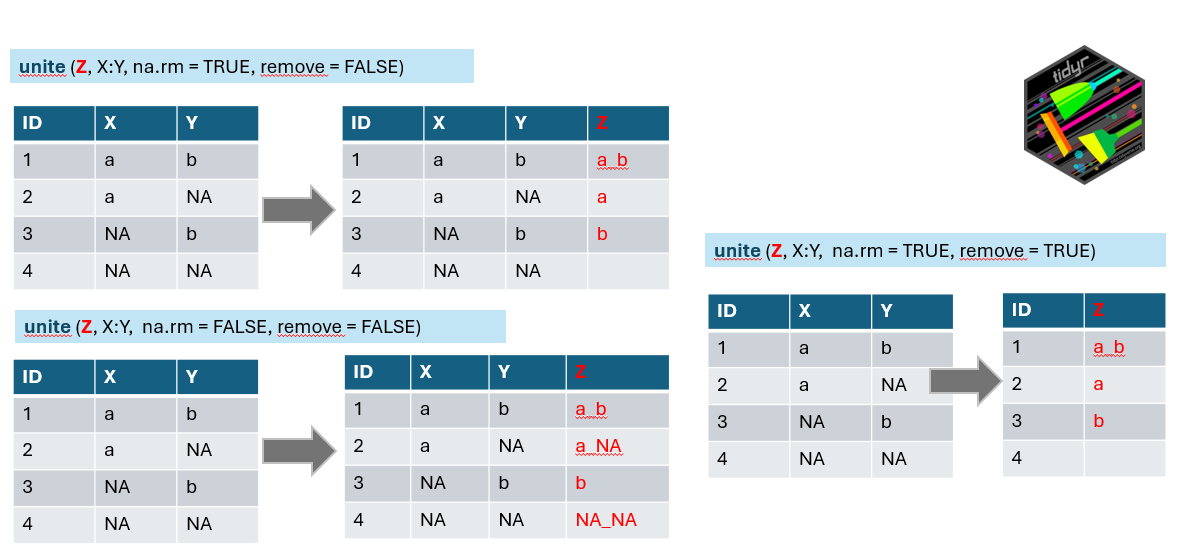
Argument na.rm indicates what to do if in one of the combined columns there is no value but NA. We have set this argument to TRUE to remove the NA. If you keep it FALSE it can happen that in some data the new string will be a_NA or NA_b, or even NA_NA (see line 4 of our example).
Remove argument set to TRUE will remove the original columns which we used to combine the new one (in the example above you will have only z). In our case we will keep original columns for visual checking and we will use select function in the next step to remove them.
Note that function that works in an opposite direction is called separate or separate_wider_delim
spe %>%
mutate(species = str_replace_all(species, " ", "_"))%>%
unite("species_layer", species,layer, na.rm = TRUE, remove = FALSE) # A tibble: 2,277 × 5
releve_nr species_layer species layer cover_perc
<dbl> <chr> <chr> <dbl> <dbl>
1 1 Acer_campestre_1 Acer_campestre 1 20
2 1 Acer_campestre_7 Acer_campestre 7 0.5
3 1 Acer_platanoides_7 Acer_platanoides 7 0.1
4 1 Anemone_6 Anemone 6 0.5
5 1 Bromus_ramosus_agg._6 Bromus_ramosus_agg. 6 0.1
6 1 Carex_digitata_6 Carex_digitata 6 3
7 1 Carex_michelii_6 Carex_michelii 6 0.1
8 1 Carex_montana_6 Carex_montana 6 0.5
9 1 Carpinus_betulus_7 Carpinus_betulus 7 0.5
10 1 Cephalanthera_damasonium_6 Cephalanthera_damasoni… 6 0.1
# ℹ 2,267 more rowsAt this point we have everything we need to use it as input for the wide format table: releve_nr. species_layer and values of the abundance saved as cover_perc. One more step is to select only these or to deselect (-) those not needed.
spe %>%
mutate(species = str_replace_all(species, " ", "_"))%>%
unite("species_layer", species,layer, na.rm = TRUE, remove = FALSE)%>%
select(releve_nr, species_layer, cover_perc)# A tibble: 2,277 × 3
releve_nr species_layer cover_perc
<dbl> <chr> <dbl>
1 1 Acer_campestre_1 20
2 1 Acer_campestre_7 0.5
3 1 Acer_platanoides_7 0.1
4 1 Anemone_6 0.5
5 1 Bromus_ramosus_agg._6 0.1
6 1 Carex_digitata_6 3
7 1 Carex_michelii_6 0.1
8 1 Carex_montana_6 0.5
9 1 Carpinus_betulus_7 0.5
10 1 Cephalanthera_damasonium_6 0.1
# ℹ 2,267 more rowsNow we can finaly use the pivot wider function to transform the data. We have to specify from where we are taking the names of new variables (names_from) and from where we should take the values which should appear in the table (values_from). Since we changed the format, all species, even those not occurring in that particular site/plot have to get some values. Therefore, one more step is to fill the empty cells by zeros using values_fill. In this case we can do that, because we know that if the species was absent its abundance was exactly 0.
spe %>%
mutate(species = str_replace_all(species, " ", "_"))%>%
unite("species_layer", species,layer, na.rm = TRUE, remove = FALSE)%>%
pivot_wider(names_from = species_layer,
values_from = cover_perc,
values_fill = 0) -> spe_widetibble(spe)# A tibble: 2,277 × 4
releve_nr species layer cover_perc
<dbl> <chr> <dbl> <dbl>
1 1 Acer campestre 1 20
2 1 Acer campestre 7 0.5
3 1 Acer platanoides 7 0.1
4 1 Anemone 6 0.5
5 1 Bromus ramosus agg. 6 0.1
6 1 Carex digitata 6 3
7 1 Carex michelii 6 0.1
8 1 Carex montana 6 0.5
9 1 Carpinus betulus 7 0.5
10 1 Cephalanthera damasonium 6 0.1
# ℹ 2,267 more rows3.2 JUICE input files
JUICE can handle the species files in long format as well and it is called database data import. We can make a selection of the important fields (releve nr, species, layer and cover) and save the file as csv. However, JUICE is primarily working with integers. Therefore, the first step is to check the cover values we have in our dataset.
spe <- read_csv("data/spe.csv") Rows: 2278 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): species, plant_group
dbl (3): releve_nr, layer, cover_perc
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.spe %>% count(cover_perc)# A tibble: 9 × 2
cover_perc n
<dbl> <int>
1 0.1 553
2 0.5 957
3 3 360
4 4 135
5 10 117
6 20 51
7 37.5 67
8 62.5 36
9 87.5 2Here we are using values of the new Braun-Blaunquet scale transformed to percentages with decimals. We can either use some crosswalk table (see the table_cover and column COVER_PERC_EVA) or change the values directly in the script as below and save the output as a csv file. I recommend using the file with original covers and not the one after merging in R. The same approach as we did here for merging covers (see function in the last section of the Turboveg to R) can be done in JUICE later on and it saves you from rounding complicated values before export.
spe %>%
select(releve_nr, species, layer, cover_perc) %>%
arrange(releve_nr) %>%
mutate (cover_perc= case_when(cover_perc==0.1 ~ 1,
cover_perc==0.5 ~ 2,
cover_perc==3 ~ 3,
cover_perc==4 ~ 4,
cover_perc==10 ~ 8,
cover_perc==20 ~ 18,
cover_perc==37.5 ~ 38,
cover_perc==62.5 ~ 63,
cover_perc==87.5 ~ 88,
TRUE ~ cover_perc)) %>%
write_excel_csv("data/spe_juice_input.csv")We will use the import through Database records. Note that sometimes it might be helpful to open the csv file in Excel and save it as csv UTF-8 again. The format seems to be the same but it respects your local settings of the environment.

Select the file and check if you have defined the positions of individual columns (1,2…) as it is in your file.
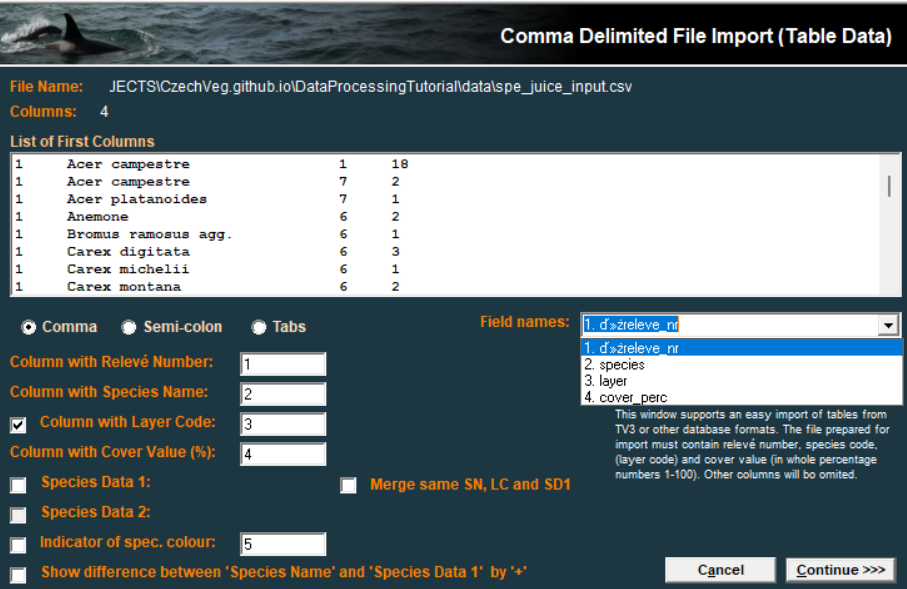
For headers we can use any selection of the header data, and import it as a second step after saving the file. Be sure to have the file arranged in the same way and to include the Relevé number.
read_csv("data/env_measured.csv")%>%
select(releve_nr,forest_type, forest_type_name, soil_pH) %>%
arrange(releve_nr) %>%
rename("Relevé number"=releve_nr)Rows: 65 Columns: 22
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): forest_type_name
dbl (21): releve_nr, forest_type, herbs, juveniles, coverE1, biomass, soil_d...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 65 × 4
`Relevé number` forest_type forest_type_name soil_pH
<dbl> <dbl> <chr> <dbl>
1 1 2 oak hornbeam forest 5.28
2 2 1 oak forest 3.24
3 3 1 oak forest 4.01
4 4 1 oak forest 3.77
5 5 1 oak forest 3.5
6 6 1 oak forest 3.8
7 7 1 oak forest 3.48
8 8 2 oak hornbeam forest 3.68
9 9 2 oak hornbeam forest 4.24
10 10 1 oak forest 4.01
# ℹ 55 more rowsNow you can save this file and import it to JUICE as you are used to importing headers.